Alain presents a methodology and Python script for exploring Active Directory users with multiple accounts in BloodHound.
BloodHound does an excellent job of allowing attackers and defenders to understand attack paths in Active Directory environments. The attack paths tracked by BloodHound involve edges representing configuration issues and attack primitives that typically have a high likelihood of being exploitable. For example, when BloodHound indicates a user has an AdminTo edge to a computer, this generally guarantees that there is a valid attack path involving Administrator access to this computer (with some exceptions like remote logons to the computer by this user being explicitly denied).
However, there are other Active Directory attack paths that are not represented by the default edges in BloodHound, as they are harder to automatically analyse and cannot be guaranteed to be exploitable in the majority of cases. A common Active Directory attack path we exploit on engagements at Insomnia Security is compromising a single account owned by a user and turning this into a compromise of other accounts owned by the same user. Discovering and understanding all of the accounts owned by a single user is not trivially automatable as every organisation and every Active Directory environment is unique. This blog post discusses some of the techniques we use to try to increase the visibility of users with multiple accounts and integrate this with BloodHound.
Prior Work
Several people in the security industry have previously published blog posts or tools to achieve similar goals using BloodHound:
- Christopher Maddalena has a blog post on performing Password Analysis With BloodHound.
- Tom Porter created the BloodHound-Owned tool which can add edges to BloodHound to track password sharing amongst other functionality. Also see the related blog post on Representing Password Reuse in BloodHound and presentation on Extending BloodHound for Red Teamers.
Users With Multiple Accounts
In more complex or more mature Active Directory environments it is increasingly likely that users have more than one Active Directory account. Common scenarios we have encountered include:
- Multiple accounts for different tiers of access within a single domain such as normal user, Local Administrator, Server Administrator, Domain Administrator, etc.
- Separate accounts for a dedicated and segregated administrative forest.
- Separate accounts across different forests belonging to different organisations or divisions (e.g. forests split per region or organisations going through mergers).
- Separate accounts for access to systems used for developing or testing.
- Separate accounts used for access to specific sensitive or privileged systems. Typically, this involves something like a user initiating a Remote Desktop connection from their day to day workstation (accessible with their low privilege account) to an administrative jump host and entering privileged credentials. Generally, anytime that a user enters passwords for different accounts using the same physical keyboard is an indication that some kind of cross-account compromise is possible (compensating controls like multi-factor authentication can make this harder to exploit).
- Storing passwords for high privilege accounts on systems accessed using low privilege accounts. We see the full range from text files on the desktop to the use of password managers with multi-factor authentication. This practice is common in cases where users are expected to have different passwords for different accounts but find it challenging to memorise multiple passwords. Regardless of the storage method, any access of high privilege passwords using a low privilege account increases the likelihood of the high privilege credentials being compromised.
- Accessing account provisioning or password reset functionality for high privilege accounts from their low privilege accounts. The most common example we see is users authenticate to helpdesk and change management systems using their low privilege accounts. The consequence of this access is that attackers can simply use a low privilege account to provision a new high privilege account in the same manner as legitimate users.
Identifying Accounts Owned By The Same User
Discovering all of the accounts owned by the same user involves different methods in every environment. In some environments with standardised account naming it is trivial to identify these accounts. In larger, older and more complex multi-forest environments it can be a nightmare juggling all of the different naming conventions and Organisational Unit structures that are being used. Typical approaches we use to identify multiple accounts owned by the same user are:
- Understanding how accounts from different tiers are labelled (e.g. bob.smith -> bob-admin).
- Searching for the same username across all domains.
- Creating a mapping between different naming conventions in different domains (e.g. bob.smith -> bsmith).
- Searching for accounts that have identical attributes such as display names, phone numbers or email addresses.
Identifying Potential Shared Passwords
If we have compromised a password (or hash) for a single account we often want to determine if the same password is used for other accounts owned by the same user. The naive way to do this is to simply attempt to authenticate to the user’s other accounts using the compromised password. We definitely use this approach, but we typically try to improve our odds of success before blindly making authentication attempts. It is also common for us to be in a situation where we have compromised low privilege accounts for several dozen users, and we want to find the most likely candidates for shared passwords rather than test every single user. The two methods we use to determine if a shared password is more likely are:
- Different accounts with Pwd-Last-Set attributes that have values close together. If a user has multiple accounts where the password was set on the same day this is often a good indicator that the same password has been used for all accounts. This is due to two reasons, firstly users struggle to manage multiple passwords and will often deliberately set all of their passwords at once to the same password to make their life easier. Secondly, different accounts for a user often get provisioned at the same time and end up on the same password expiration cycle. When passwords for multiple accounts expire on the same day, it’s more likely that users are going to get frustrated and use the same password.
- Checking other passwords belonging to the user to see if they are the same. It can be tempting to immediately check for password sharing between a user’s low privilege account and their high privilege account. However, it’s less noisy to first try against other low privilege accounts owned by the user (if they have them), or collect other saved credentials to see if the user has a habit of using the same password (e.g. saved passwords in the browser).
Example
During an exercise, we were in a situation where we had completely compromised two forests (Forest A and Forest B) and were attempting to compromise a third forest (Forest C). The forest structure was intended to only allow downwards access from Forest C -> Forest B -> Forest A and not allow upwards access from Forest B -> Forest C. There was a small number of accounts with cross-forest group memberships between Forest B and Forest C, but this provided access in the wrong direction (i.e. from Forest C downwards into Forest B). We performed BloodHound session collection and checked logon event logs in Forest B in the hopes of finding a user from Forest C logged into a system in Forest B with no luck.
At this stage, we created a mapping of usernames from Forest A and Forest B against those in Forest C to find any users from the compromised forests in the target forest. This produced a list of approximately 40 users who we could test for password sharing. We checked the Pwd-Last-Set attribute for all accounts owned by these 40 users across all three forests, and found a single user who had Pwd-Last-Set values on the same calendar day for all of their accounts that looked similar to the following:
23 Sep 2019 10:26:58 - FORESTA\bsmith
23 Sep 2019 10:10:31 - FORESTB\bob.smith
23 Sep 2019 09:52:28 - FORESTB\bob-admin
23 Sep 2019 09:45:29 - FORESTC\bob.smith
This was a promising indication that this user was likely to be using the same password for all of their accounts. The Pwd-Last-Set values suggested that the user probably logged into their account in Forest C, and set the password before moving downwards to their accounts in Forest B and Forest A and setting the passwords on the same day. Because we had compromised Forest A and Forest B in this case, we were also able to retrieve the passwords for the user’s accounts in these forests. These password hashes were all identical which confirmed that password sharing was present between at least Forest A and Forest B. This further improved the odds that the user’s account in Forest C would be using the same password. Through exploiting this user’s shared password, it was possible to gain a foothold in Forest C even though there were no obvious attack paths visible through BloodHound.
Automating Discovery Of Multiple Accounts
The analysis performed during the above example was only semi-automated and involved a combination of Neo4j queries that worked in that specific environment, to find users with multiple accounts along with eyeballing Pwd-Last-Set values in the output to find a good candidate user. This is perfectly feasible in smaller environments but becomes more unwieldy the larger the environment is. Also when you encounter environments that have gone through multiple iterations of bizarre naming conventions, you really need to be able to automate (and document) all the methods you are using to discover multiple accounts owned by the same user. Another issue with performing this analysis outside of BloodHound is that you can end up doing lots of backwards and forwards between your list of candidate users with shared passwords, and checking what attack paths that a user’s account has (i.e. there is no point compromising an account with a shared password if it doesn’t get you anywhere).
For these reasons I ended up creating a more generic Python script which is available on GitHub to help automate the process. This script can be used to discover multiple accounts owned by the same user via most of the common methods and add a SameUser edge between them in BloodHound. The script can then compare the Pwd-Last-Set attribute of all users with a SameUser relationship and add a SharedPassword edge if these values are within a certain range. These edges can then be used to perform path finding via a cross-account compromise. Hopefully this script is a good starting point for anyone else who needs to automate this type of account discovery at scale.
Script Setup
Before using the Python script you will need to update the Neo4j hostname, username and password which is currently hardcoded at the top of the Python script.
uri = 'bolt://127.0.0.1:7687'
username = 'neo4j'
password = 'changeme'
Adding SameUser Relationships
The most basic usage is to add SameUser relationships between users with the same username, display name or email address. You might use all three of these methods in succession to make sure you are getting good coverage of all accounts users.
sameuser.py --same-username
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... relationship already exists
sameuser.py --same-email
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... relationship already exists
sameuser.py --same-displayname
[email protected] -> [email protected]... relationship already exists
[email protected] -> [email protected]... relationship already exists
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... relationship already exists
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... added SameUser relationship
There is also an option to use a Python regular expression to do find and replace style manipulation of usernames and add SameUser relationships. This is useful if you know specific username schemes are being used in an environment.
sameuser.py --same-regex-find "(.*)\..*(@.*)" --same-regex-replace "\1-DA\2"
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... added SameUser relationship
You can also supply an explicit list of the users you want to match to the script as a CSV file. This is useful in cases where it’s difficult to match based on similarities in the username or attributes. Additionally, this can be useful in cases where you get too many false positives using automatic matching methods or you only want to add SameUser relationships for a specific user.
sameuser.py --same-csv test.csv
[email protected] -> [email protected]... added SameUser relationship
[email protected] -> [email protected]... added SameUser relationship
Querying SameUser Relationships
Once you have some SameUser relationships you can begin to query them like any other BloodHound edge. For example, you could find all Sameuser edges between all users with a query like:
MATCH (a:User), (b:User), p=(a)-[r:SameUser]-(b) RETURN p
However, this query isn’t very useful for discovering anything interesting. A more useful query might be to do something like take a specific user of interest and return their other accounts:
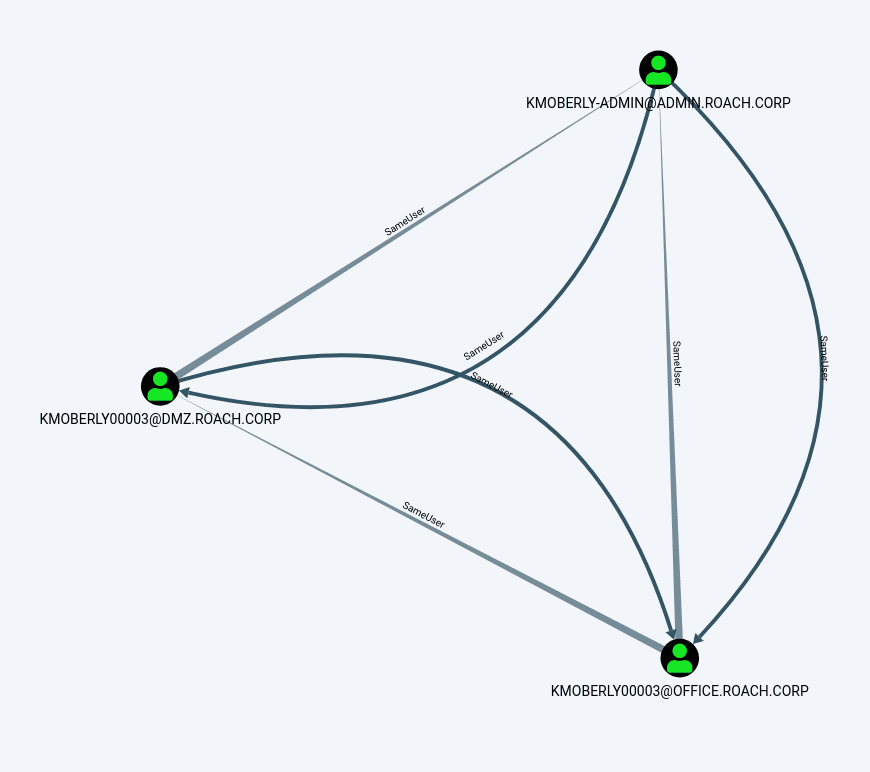
MATCH (a:User {name:"[email protected]"}), (b:User), p=(a)-[r:SameUser*1..]-(b) RETURN p
We can see that this user has accounts in three different domains that are now associated with each other through SameUser relationships:
These SameUser edges can now be used for path finding in combination with existing BloodHound edges. For example, if we select a user and execute the built-in Reachable High Value Targets query in BloodHound, we can now see paths that include SameUser edges. An example path is shown below where SameUser relationships could potentially be part of an attack path between domains. Of course this is very much dependent on the SameUser relationship being traversable which may or may not be the case in a specific environment.

In practice the SameUser edges are more useful for simpler use cases involving fewer hops and less uncertainty. Most commonly we use SameUser edges for checking if any currently compromised users also have another account in a high value group:
MATCH (a:User {owned:true}), (b:User), (c:Group {highvalue:true}), p=(a)-[r1:SameUser*1..]-(b)-[r2:MemberOf*..1]->(c) RETURN p
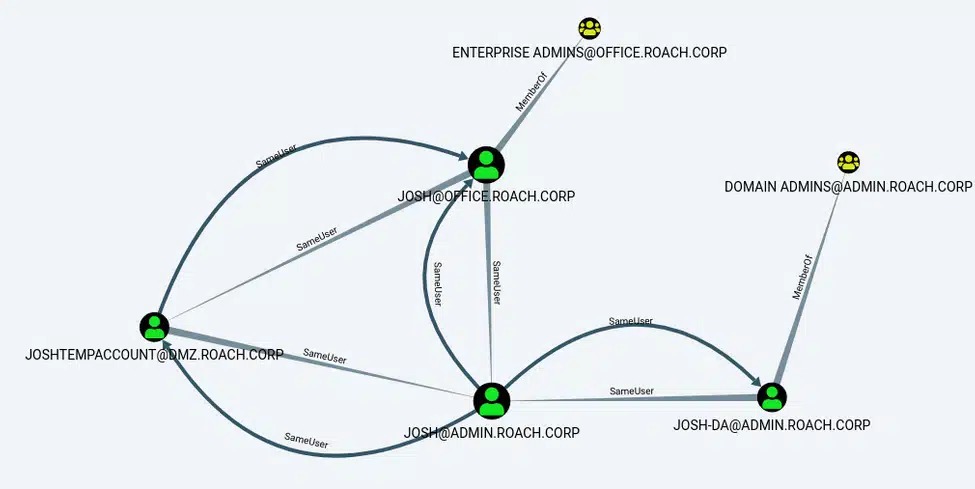
In this case, we have compromised the [email protected] user and can see that this user has other accounts in other domains that are members of privileged groups. With this information we now know it’s worth our time seeing if we can traverse from the [email protected] account to other accounts owned by this user. For example, we might try the compromised password (or hash) against the user’s other accounts to see if a shared password is being used. Alternatively, we might check all systems where [email protected] is known to login for any active sessions or historical logins belonging to the user’s other accounts.
Adding SharedPassword Relationships
After adding SameUser relationships, you can now analyse the Pwd-Last-Set attribute between all users with relationship. The Python script can be used to check the Pwd-Last-Set attributes between users with SameUser relationships, and add a SharedPassword relationship if the difference is within a set number of hours. For example, you can add a SharedPassword relationship between any accounts owned by the same user who have password last set dates within 12 hours of each other:
sameuser.py --password 12
Added SharedPassword relationships between 949 user pairs
Every environment is different and has its own processes and culture with regards to setting and changing passwords. You will need to use context from your environment and a bit of guesswork to find a time difference that works well in your environment and limits false positives. Typically, we find that passwords for different accounts set within several hours of each other are a good indicator for potential password sharing. Anything longer than 24 hours tends to be less reliable and introduce too much noise.
Also be wary of accounts that have passwords that were set too close together to have possibly been set manually by a human. Password last set timestamps that are exactly the same (or within seconds of each other) can be an indicator of automated user deployment or automated password rotation systems. Sometimes this is a good thing for an attacker and the automated system is helpfully setting the same password for all of the accounts. Other times this can mean that a unique password was automatically chosen for each account and provided to the user.
Querying SharedPassword Relationships
You can now query SharedPassword edges and find all users with a potentially shared password with a query like:
MATCH (a:User), (b:User), p=(a)-[r:SharedPassword]-(b) RETURN p
This query might be useful in a small environment where you only have dozens of users with potential password sharing. We often deal with environments with tens of thousands of users where this query will result in giant blob of potential password sharing as shown below:

Let’s revisit the query from earlier to do something more useful. This is the same query to find compromised users who also have another account in a high value group, but this time we have also added the SharedPassword edge
MATCH (a:User {owned:true}), (b:User), (c:Group {highvalue:true}), p=(a)-[r1:SameUser|SharedPassword*1..]-(b)-[r2:MemberOf*..1]->(c) RETURN p
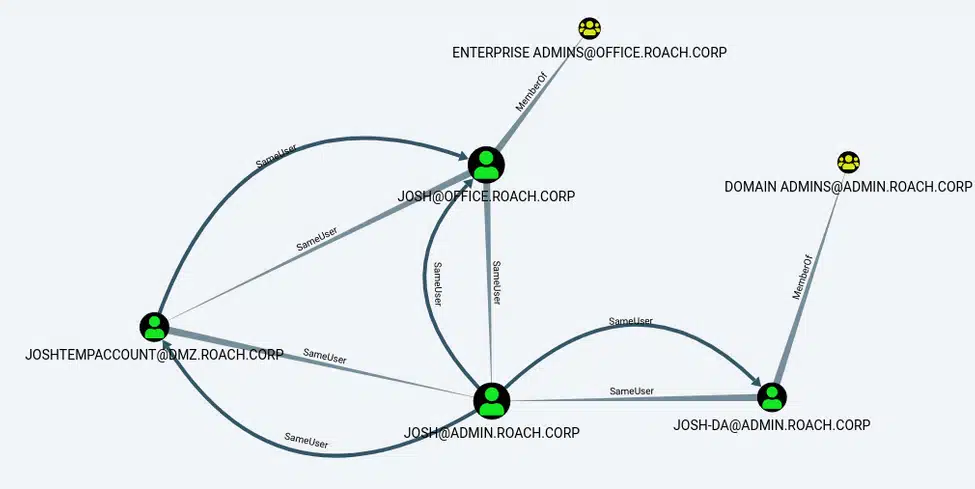
We can see that there is now a SharedPassword edge between the [email protected] and [email protected] users because the password last set timestamp for these accounts is within 12 hours of each other. We can also see that there isn’t a SharedPassword edge for any of the other users like [email protected]. This information suggests that if we were to check for a shared password we would probably have a better chance of success with the [email protected] account.
The most common place we use the SharedPassword edge is to look for attack paths between domains or forests when there are no other obvious attack paths. We often find ourselves in a situation where we have completely compromised a domain like OFFICE.ROACH.CORP, and want to move to another domain like ADMIN.ROACH.CORP but don’t have any attack paths in BloodHound. A simple query to look for all accounts in one domain with potential shared passwords with accounts in another domain looks like:
MATCH (a:User {domain:"OFFICE.ROACH.CORP"}), (b:User {domain:"ADMIN.ROACH.CORP"}), p=(a)-[r:SharedPassword*..1]->(b) RETURN p
Unless you are dealing with a small number of results you will probably end up wanting to return a list of results rather than a graph with a query like:
MATCH (a:User {domain:"OFFICE.ROACH.CORP"}), (b:User {domain:"ADMIN.ROACH.CORP"}), p=(a)-[r:SharedPassword*..1]->(b) RETURN a.name, a.pwdlastset, b.name, b.pwdlastset
This is sufficient for creating a large list of potential users to test for shared passwords to gain low privilege access to the target domain. In this particular environment it returns over 300 pairs of users which we could test for shared passwords. However, in practice it is pretty rare that we end up blindly trying to authenticate as a large number of users with an unknown level of privilege. Usually we first look for quick wins to immediately gain privileged access to the target domain instead. For example, we might limit our query to only find potential password sharing with users in the target domain who are members of high value groups:
MATCH (a:User {domain:"OFFICE.ROACH.CORP"}), (b:User {domain:"ADMIN.ROACH.CORP"}), (c:Group {highvalue:true}), p=(a)-[r:SharedPassword*..1]->(b)-[r2:MemberOf*..1]->(c) RETURN p
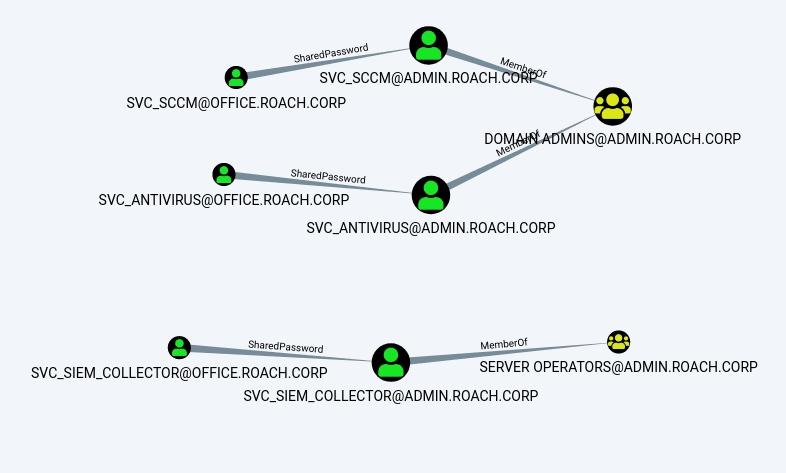
We can see that this has returned three service accounts that exist in both domains that are potentially sharing passwords and that are members of high value groups in the target domain. If we have compromised OFFICE.ROACH.CORP we can steal the credentials for these accounts and then try the credentials against the accounts with the same name in the ADMIN.ROACH.CORP domain.
Clearing Relationships
The Python script also includes some flags to clear out the SameUser and SharedPassword relationships that you have added. Why would you want to clear these relationships? The most obvious problem you will run into is that a specific way of identifying accounts with the same owner doesn’t work well in your environment. This usually happens when you make an assumption about a naming scheme for translating normal account names to privileged account names that is incorrect. The other problem you are likely to encounter with these relationships is that they can get in the way once you are finished with looking at cross-account attack paths. A lot of BloodHound path finding queries aren’t explicitly about the edge types that are included, and this might have undesirable results if you don’t want to include SameUser and SharedPassword edge types.
This might be undesirable if you are finished with looking at cross-account attack paths and want to look at attack paths using the default edges only. For this reason, the script includes commands to easily remove SameUser and SharedPassword edges.
sameuser.py --clear-user
Clearing all SameUser relationships... OK
sameuser.py --clear-password
Clearing all SharedPassword relationships... OK
sameuser.py --clear
Clearing all SameUser relationships... OK
Clearing all SharedPassword relationships... OK
Conclusions and Caveats
Hopefully this Python script and the associated methodology is useful to help you find some new potential attack paths, or give you ideas on how you can extend BloodHound to automate your own attack paths. This isn’t a perfect tool or methodology and it is easy to shoot yourself in the foot or go chasing dead ends if you aren’t careful. Keep in mind the following while using this approach to identifying users with multiple accounts and potential password sharing:
- A good understanding of the account naming conventions used in an environment is necessary to accurately discover instances of users with multiple accounts. It is easy to make assumptions based on a small sample of account names and end up with incomplete or garbage data as a result.
- The
SameUserandSharedPasswordedges only show a potential attack path and don’t have anywhere near the same level of certainty as the built-in edges in BloodHound. - There are many reasons that two accounts from the same user can have similar password last set dates other than password sharing. For example, the accounts may have been provisioned at the same time or may be subject to similar password rotation policies. You will need to use your context and intuition about a specific environment to determine if you can rely on this as an indicator of password sharing.
- Path finding queries that don’t specify the edge types will use the
SameUserandSharedPasswordedges. If you don’t want to include these edge types in queries then either be specific about the edge types you are looking for or clear out these relationships if they get in the way. - The Python script is intended to be compatible with BloodHound 3.0.2+ and Neo4j 4.0.1+. You might experience issues if you try to use this script with older versions of BloodHound and Neo4j.